1.巧用数组下标
数组的下标是一个隐含的很有用的数组,特别是在统计一些数字,或者判断一些整型数是否出现过的时候。例如,给你一串字母,让你判断这些字母出现的次数时,我们就可以把这些字母作为下标,在遍历的时候,如果字母a遍历到,则arr[a]就可以加1了,即 arr[a]++;
通过这种巧用下标的方法,我们不需要逐个字母去判断。
我再举个例子:
问题:给你n个无序的int整型数组arr,并且这些整数的取值范围都在0-20之间,要你在 O(n) 的时间复杂度中把这 n 个数按照从小到大的顺序打印出来。
对于这道题,如果你是先把这 n 个数先排序,再打印,是不可能O(n)的时间打印出来的。但是数值范围在 0-20。我们就可以巧用数组下标了。把对应的数值作为数组下标,如果这个数出现过,则对应的数组加1。
代码如下:
1 | public void f(int arr[]) { |
提醒:可以左右滑动
利用数组下标的应用还有很多,大家以后在遇到某些题的时候可以考虑是否可以巧用数组下标来优化。
2.巧用取余
有时候我们在遍历数组的时候,会进行越界判断,如果下标差不多要越界了,我们就把它置为0重新遍历。特别是在一些环形的数组中,例如用数组实现的队列。往往会写出这样的代码:
1 | for (int i = 0; i < N; i++) { |
实际上我们可以通过取余的方法来简化代码
1 | for (int i = 0; i < N; i++) { |
3.巧用双指针
对于双指针,在做关于单链表的题是特别有用,比如“判断单链表是否有环”、“如何一次遍历就找到链表中间位置节点”、“单链表中倒数第 k 个节点”等问题。对于这种问题,我们就可以使用双指针了,会方便很多。我顺便说下这三个问题怎么用双指针解决吧。
例如对于第一个问题
我们就可以设置一个慢指针和一个快指针来遍历这个链表。慢指针一次移动一个节点,而快指针一次移动两个节点,如果该链表没有环,则快指针会先遍历完这个表,如果有环,则快指针会在第二次遍历时和慢指针相遇。
对于第二个问题
一样是设置一个快指针和慢指针。慢的一次移动一个节点,而快的两个。在遍历链表的时候,当快指针遍历完成时,慢指针刚好达到中点。
对于第三个问题
设置两个指针,其中一个指针先移动k个节点。之后两个指针以相同速度移动。当那个先移动的指针遍历完成的时候,第二个指针正好处于倒数第k个节点。
你看,采用双指针方便多了吧。所以以后在处理与链表相关的一些问题的时候,可以考虑双指针哦。
4.巧用移位运算
有时候我们在进行除数或乘数运算的时候,例如n / 2,n / 4, n / 8这些运算的时候,我们就可以用移位的方法来运算了,这样会快很多。
例如:
n / 2 等价于 n >> 1
n / 4 等价于 n >> 2
n / 8 等价于 n >> 3。
这样通过移位的运算在执行速度上是会比较快的,也可以显的你很厉害的样子,哈哈。
还有一些 &(与)、|(或)的运算,也可以加快运算的速度。例如判断一个数是否是奇数,你可能会这样做
1 | if(n % 2 == 1){ |
不过我们用与或运算的话会快很多。例如判断是否是奇数,我们就可以把n和1相与了,如果结果为1,则是奇数,否则就不会。即
1 | if(n & 1 == 1){ |
具体的一些运算技巧,还得需要你们多在实践中尝试着去使用,这样用久后就会比较熟练了。
5.设置哨兵位
在链表的相关问题中,我们经常会设置一个头指针,而且这个头指针是不存任何有效数据的,只是为了操作方便,这个头指针我们就可以称之为哨兵位了。
例如我们要删除头第一个节点是时候,如果没有设置一个哨兵位,那么在操作上,它会与删除第二个节点的操作有所不同。但是我们设置了哨兵,那么删除第一个节点和删除第二个节点那么在操作上就一样了,不用做额外的判断。当然,插入节点的时候也一样。
有时候我们在操作数组的时候,也是可以设置一个哨兵的,把arr[0]作为哨兵。例如,要判断两个相邻的元素是否相等时,设置了哨兵就不怕越界等问题了,可以直接arr[i] == arr[i-1]?了。不用怕i = 0时出现越界。
当然我这只是举一个例子,具体的应用还有很多,例如插入排序,环形链表等。
6.与递归有关的一些优化
(1)对于可以递归的问题考虑状态保存
当我们使用递归来解决一个问题的时候,容易产生重复去算同一个子问题,这个时候我们要考虑状态保存以防止重复计算。例如我随便举一个之前举过的问题
问题:一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法?
这个问题用递归很好解决。假设 f(n) 表示n级台阶的总跳数法,则有
f(n) = f(n-1) + f(n - 2)。
递归的结束条件是当0 <= n <= 2时, f(n) = n。因此我们可以很容易写出递归的代码
1 | public int f(int n) { |
不过对于可以使用递归解决的问题,我们一定要考虑是否有很多重复计算。显然对于 f(n) = f(n-1) + f(n-2) 的递归,是有很多重复计算的。如
就有很多重复计算了。这个时候我们要考虑状态保存。例如用hashMap来进行保存,当然用一个数组也是可以的,这个时候就像我们上面说的巧用数组下标了。可以当arr[n] = 0时,表示n还没计算过,当arr[n] != 0时,表示f(n)已经计算过,这时就可以把计算过的值直接返回回去了。因此我们考虑用状态保存的做法代码如下:
1 | //数组的大小根据具体情况来,由于int数组元素的的默认值是0 |
这样,可以极大着提高算法的效率。也有人把这种状态保存称之为备忘录法。
(2).考虑自底向上
对于递归的问题,我们一般都是从上往下递归的,直到递归到最底,再一层一层着把值返回。
不过,有时候当n比较大的时候,例如当 n = 10000时,那么必须要往下递归10000层直到 n <=2 才将结果慢慢返回,如果n太大的话,可能栈空间会不够用。
对于这种情况,其实我们是可以考虑自底向上的做法的。例如我知道
f(1) = 1;
f(2) = 2;
那么我们就可以推出 f(3) = f(2) + f(1) = 3。从而可以推出f(4),f(5)等直到f(n)。因此,我们可以考虑使用自底向上的方法来做。
代码如下:
1 | public int f(int n) { |
我们也把这种自底向上的做法称之为递推。
总结一下
当你在使用递归解决问题的时候,要考虑以下两个问题
(1). 是否有状态重复计算的,可不可以使用备忘录法来优化。
(2). 是否可以采取递推的方法来自底向上做,减少一味递归的开销。
7.找出两个没有重复的数
对于第一题【找出没有重复的数】
给你一组整型数据,这些数据中,其中有一个数只出现了一次,其他的数都出现了两次,让你来找出一个数 。
有人问如果有2个数出现了一次,其他数都出现了一次,那还能用位运算来找出这两个数吗?
答是必须的,假如这两个出现一次的 数 分别为 A, B,则所有 数 异或后的结果为 A^B,这时我们遇到的问题是无法确定 A,B的值。
由于 A 和 B 是不一样的值,所以 A^B 的结果不为 0,也就是说,这个异或值的二进制中某一位为1。显然,A 和 B 中有且仅有一个数的相同位上也为 1。
这个时候,我们可以把所有 数 分为两类,一类在这个位上为 1,另一类为 0,那么对于这两类,一类会含有 A,另一类会含有 B。于是,我们可以分别计算这两类 数 的异或值,即可得到 A 和 B 的值。
8.找出不大于N的最大的2的幂指数
传统的做法就是让 1 不断着乘以 2,代码如下:
1 | int findN(int N){ |
这样做的话,时间复杂度是 O(logn),那如果改成位运算,该怎么做呢?我刚才说了,如果要弄成位运算的方式,很多时候我们把某个数拆成二进制,然后看看有哪些发现。这里我举个例子吧。
例如 N = 19,那么转换成二进制就是 00010011(这里为了方便,我采用8位的二进制来表示)。那么我们要找的数就是,把二进制中最左边的 1 保留,后面的 1 全部变为 0。即我们的目标数是 00010000。那么如何获得这个数呢?相应解法如下:
1、找到最左边的 1,然后把它右边的所有 0 变成 1
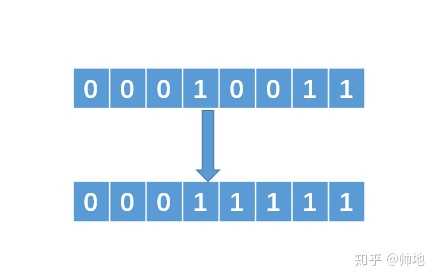
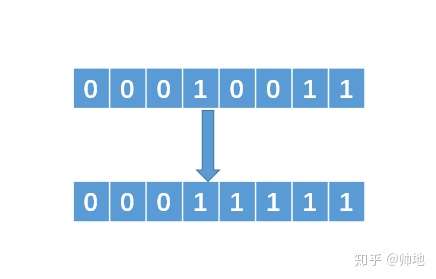
2、把得到的数值加 1,可以得到 00100000即 00011111 + 1 = 00100000。
3、把 得到的 00100000 向右移动一位,即可得到 00010000,即 00100000 >> 1 = 00010000。
那么问题来了,第一步中把最左边 1 中后面的 0 转化为 1 该怎么弄呢?我先给出代码再解释吧。下面这段代码就可以把最左边 1 中后面的 0 全部转化为 1,
1 | n |= n >> 1; |
就是通过把 n 右移并且做或运算即可得到。我解释下吧,我们假设最左边的 1 处于二进制位中的第 k 位(从左往右数),那么把 n 右移一位之后,那么得到的结果中第 k+1 位也必定为 1,然后把 n 与右移后的结果做或运算,那么得到的结果中第 k 和 第 k + 1 位必定是 1;同样的道理,再次把 n 右移两位,那么得到的结果中第 k+2和第 k+3 位必定是 1,然后再次做或运算,那么就能得到第 k, k+1, k+2, k+3 都是 1,如此往复下去….
最终的代码如下
1 | int findN(int n){ |
这种做法的时间复杂度近似 O(1),重点是,高逼格。
9.判断一个正整数 N 是否为 2 的幂次方。
如果一个数是 2 的幂次方,意味着 N 的二进制表示中,只有一个位 是1,其他都是0。我举个例子,例如
2^0 = 0…..0001
2^1 = 0…..0010
2^2 = 0….0100
2^3 = 0..01000
…..
所以呢,我们只需要判断N中的二进制表示法中是否只存在一个 1 就可以了。不过我们可以用上面第七题中的做法找出不大于N的最大的2的幂指数 M,然后判断找处理的那个数M是否和N相等。这种做法,比一个一个着去统计N的二进制位中是否只有一个1快多了。
所以呢,可以写出如下的代码
1 | boolean judge(int n){ |
然后,还有更加牛逼的解法,代码如下:
1 | boolean judege(int n){ |
卧槽,这也太牛逼了吧,一行代码解决,一行代码解决。这里我解释一下, n & (n - 1) 这个运算,会把 n 的二进制位表示法中最左边的 1 变成 0。所以呢,经过这个运算之后,如果 n & ( n - 1) 的结果是 0,说明 n 中只有一个 1。牛逼啊!

